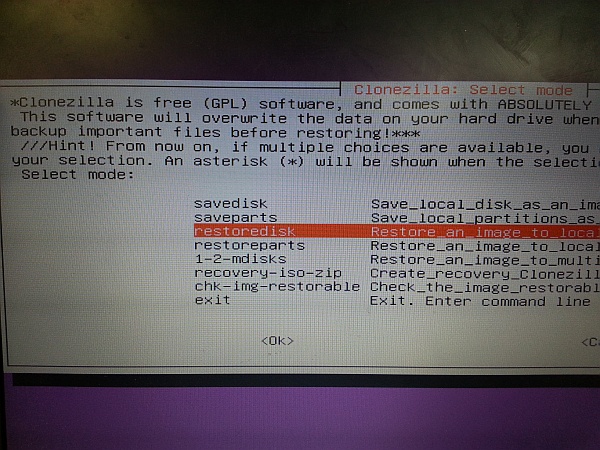
[easyreview title=”Complexity rating” icon=”geek” cat1title=”Level of experience required, to follow this how-to.” cat1detail=”We’re pulling together a few sophisticated components here, but keep your eye on the ball and you’ll be okay.” cat1rating=”4″ overall=”false”]
Laravel Tutorials
- Part 1: Installation
- Part 2: Orientation
- Part 3: Using External Libraries
- Part 4: Database Management Through Migrations
- Part 5: Using Databases
- Part 6: Virtualised development environment – Laravel Homestead
Introduction
It has been a while since I have had time to work on Laravel development or indeed write a tutorial. And since then, I have decommissioned my main web development server in favour of a Synology NAS. Dummy and I use a third party hosting service for hosting our clients’ web sites and our own. This shared hosting service comes with limitations that make it impossible to install Laravel through conventional means
So instead, I’m setting up a virtual development environment, that will run on the same laptop that I use for code development. Once development is complete, I can upload the whole thing to the shared hosting service. Getting this set up is surprisingly complicated, but once you’ve worked through all these steps, you’ll have a flexible and easy-to-use environment for developing and testing your Laravel websites. This article assumes we’re running Windows.
Components
 VirtualBox enables you to run other operating systems on existing hardware, without wiping anything out. Your computer can run Windows and then through VirtualBox, it can run one or more other systems at the same time. A computer within a computer. Or in this case, a server within a computer. Download VirtualBox here and install it.
VirtualBox enables you to run other operating systems on existing hardware, without wiping anything out. Your computer can run Windows and then through VirtualBox, it can run one or more other systems at the same time. A computer within a computer. Or in this case, a server within a computer. Download VirtualBox here and install it. Vagrant enables the automation of much of the process of creating these “virtual computers” (usually called virtual machines). Download Vagrant here and install it.
Vagrant enables the automation of much of the process of creating these “virtual computers” (usually called virtual machines). Download Vagrant here and install it. Git for Windows. If you’re a developer, chances are you know a bit about Git, so I’ll not go into detail here. Suffice it to say that you’ll need Git for Windows for this project: here.
Git for Windows. If you’re a developer, chances are you know a bit about Git, so I’ll not go into detail here. Suffice it to say that you’ll need Git for Windows for this project: here. PuTTY comes with an SSH key pair generator, which you’ll need if you don’t already have a public/private key pair. Grab the installer here.
PuTTY comes with an SSH key pair generator, which you’ll need if you don’t already have a public/private key pair. Grab the installer here. PHP for Windows. This is not used for powering your websites, but is used by Composer (next step). I suggest downloading the “VC11 x86 Thread Safe” zip file from here. Extract all files to C:\php. There’s no setup file for this. Rename the file php.ini-development to php.ini and remove the semicolon from the line
PHP for Windows. This is not used for powering your websites, but is used by Composer (next step). I suggest downloading the “VC11 x86 Thread Safe” zip file from here. Extract all files to C:\php. There’s no setup file for this. Rename the file php.ini-development to php.ini and remove the semicolon from the line ;extension=php_openssl.dll. Find a line containing “;extension_dir” and change it toextension_dir = "ext" Composer for Windows. Composer is a kind of software component manager for PHP and we use it to install and set up Laravel. Download the Windows installer here and install.
Composer for Windows. Composer is a kind of software component manager for PHP and we use it to install and set up Laravel. Download the Windows installer here and install.
SSH key pair
You’ll need an SSH key pair later in this tutorial. If you don’t already have this, generate as follows:
- Start PuTTY Key Generator. (It may be called “PuTTYgen” in your Start Menu.)
- I would suggest accepting the defaults of a 2048-bit SSH-2 RSA key pair. Click “Generate” and move your mouse around as directed by the program.
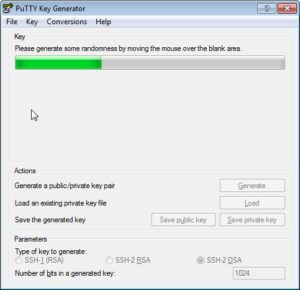
- You can optionally give the key a passphrase. If you leave the passphrase blank, you can ultimately use your key for password-less logins. The drawback is that if your private key ever falls into the wrong hands, an intruder can use the key in the same way. Make your decision, then save the public and private keys. You should always protect your private key. If you left the passphrase blank, treat it like a plain text password. I tend to save my key pairs in a directory .ssh, under my user folder.
- Use the “Save private key” button to save your public key (I call it id_rsa).
- Don’t use the “Save public key” button – that produces a key that won’t work well in a Linux/Unix environment (which your virtual development box will be). Instead, copy the text from the “Key” box, under where it says “Public key for pasting into OpenSSH authorized_keys file:”. Save this into a new text file. I call my public key file “id_rsa.pub”.
Install the Laravel Installer (sounds clumsy, huh?!)
- Load Git Bash.
- Download the Laravel installer with this command:
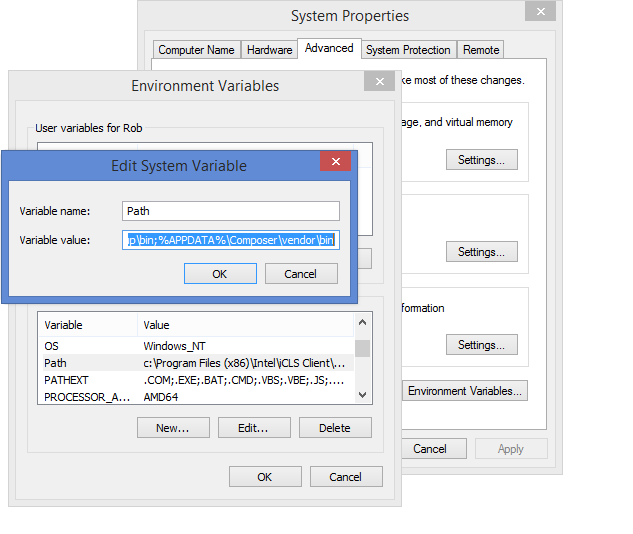
composer global require "laravel/installer=~1.1". This will take a few minutes, depending on the speed of your connection. - Ideally, you want the Laravel executable in your system path. On Windows 7/8, from Windows/File Explorer, right-click “My Computer”/”This PC”, then click Properties. Click Advanced System Settings. Click the Environment Variables button. Clik Path in the System variables section (lower half of the dialogue) then click Edit. At the very end of the Variable value field, add “;%APPDATA%\Composer\vendor\bin”.
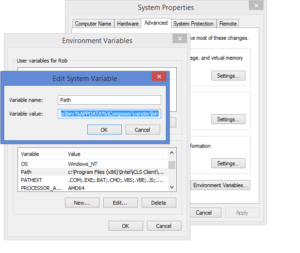
Click OK as needed to save changes. Git Bash won’t have access to that new PATH variable until you’ve exited and restarted.
Create Laravel Project
All your Laravel projects will be contained and edited within your Windows file system. I use NetBeans for development and tend to keep my development sites under (e.g.): C:\Users\Geek\Documents\NetBeansProjects\Project World Domination. Create this project as follows:
- Fire up Git Bash. This makes sure everything happens in the right place. The remaining commands
shown beloware from this shell. - Change to the directory above wherever you want the new project to be created.
cd ~/NetBeansProjects - Install Laravel:
laravel new "Project World Domination"
Note: if the directory “Project World Domination” already exists, this command will fail with an obscure error. - That’s it for this stage. Were you expecting something more complicated?
Laravel Homestead
Homestead is a pre-built development environment, consisting of Ubuntu, a web server, PHP, MySQL and a few other bits and bobs. It’s a place to host your Laravel websites while you’re testing them locally. Follow these steps to get it up and running:
- From a Git Bash prompt, change to your user folder. Make sure this location has sufficient space for storing virtual machines (800MB+ free).
cd ~ - Make the Homestead Vagrant “box” available to your system.
vagrant box add laravel/homestead
This downloads 800MB or so and may take a while. - Clone the Homestead repository into your user folder.
git clone https://github.com/laravel/homestead.git Homestead
This should be pretty quick and results in a new Homestead folder containing various scripts and configuration items for the Homestead virtual machine. - Edit the Homestead.yaml file inside the Homestead directory. In the section “authorize”, enter the path to your public SSH key (see above). Similarly, enter the path to your private key in the “keys” section.
- Vagrant can easily synchronise files between your PC and the virtual machine. Any changes in one place instantly appear in the other. So you could for example in the “folders” section, map C:\Users\Fred\Code (on your Windows machine) to /home/vagrant/code (on the virtual machine). In my case, I’ve got this:
folders:
- map: ~/Documents/NetBeansProjects
to: /home/vagrant/Projects
- We’re going to create a fake domain name for each project. Do something like this in the Homestead.yaml file:
sites:
- map: pwd.localdev
to: /home/vagrant/Projects/Project World Domination/public
Of course, if you put “http://pwd.localdev” in your browser, it will have no idea where to go. See the next section “Acrylic DNS proxy” for the clever trick that will make this all possible. - To fire up the Homestead virtual environment, issue the command
vagrant upfrom the Homestead directory. This can take a while and may provoke a few security popups.
Here’s the complete Homestead.yaml file:
---
ip: "192.168.10.10"
memory: 2048
cpus: 1
authorize: ~/.ssh/id_rsa.pub
keys:
- ~/.ssh/id_rsa
folders:
- map: ~/Documents/NetBeansProjects
to: /home/vagrant/Projects
sites:
- map: pwd.localdev
to: /home/vagrant/Projects/Project World Domination/public
variables:
- key: APP_ENV
value: local
At this point, you should be able to point your browser to http://127.0.0.1:8000. If you have created a Laravel project as above, and everything has gone well, you’ll see the standard Laravel “you have arrived” message. The Homestead virtual machine runs the Nginx webserver and that webserver will by default give you the first-mentioned web site if you connect by IP address.

VirtualBox is configured to forward port 8000 on your computer to port 80 (the normal port for web browsing) on the virtual machine. In most cases, you can connect directly to your virtual machine instead of via port forwarding. You’ll see in the Homestead.yaml file that the virtual machine’s IP address is set to 192.168.10.10. So generally (if there are no firewall rules in the way), you can browse to http://127.0.0.1:8000 or http://192.168.10.10 (the port number 80 is assumed, if omitted). Both should work. Personally I prefer the latter.
Acrylic DNS proxy
Of course we want to be able to host multiple development websites on this virtual machine. To do this, you need to be able to connect to the web server by DNS name (www.geekanddummy.com), not just by IP address. Many tutorials on Homestead suggest editing the native Windows hosts file, but to be honest that can be a bit of a pain. Why? Because you can’t use wildcards. So your hosts file ends up looking something like this:
127.0.0.1 pwd.local
127.0.0.1 some.other.site
127.0.0.1 override.com
127.0.0.1 webapp1.local
127.0.0.1 webapp2.local
(If you’re using 192.168.10.10, just replace 127.0.0.1 in the above example.) So this can go on and on, if you’re developing a load of different sites/apps on the same Vagrant box. Wouldn’t it be nice if you could just put a single line, 127.0.0.1 *.local? This simply doesn’t work in a Windows hosts file.
And this is where the Acrylic DNS proxy server comes in. It has many other great features, but the one I’m particularly interested in is the ability to deal with wildcard entries. All DNS requests go through Acrylic and any it can’t respond to, it sends out to whichever other DNS servers you configure. So it sits transparently between your computer and whatever other DNS servers you normally use.
The Acrylic website has instructions for Windows OSes – you have to configure your network to use Acrylic instead of any other DNS server. Having followed those instructions, we’re now most interested in is the Acrylic hosts file. You should have an entry in your Start menu saying “Edit Acrylic hosts file”. Click that link to open the file.
Into that file, I add a couple of lines (for both scenarios, port forwarding and direct connection, so that both work):
127.0.0.1 *.localdev
192.168.10.10 *.localdev
I prefer using *.localdev, rather than *.local for technical reasons (.local has some peculiarities).
This now means that I can now put in my Homestead.yaml file the following:
sites:
- map: site1.localdev
to: /home/vagrant/Projects/site1/public
- map: site2.localdev
to: /home/vagrant/Projects/site2/public
- map: site3.localdev
to: /home/vagrant/Projects/site3/public
- map: site4.localdev
to: /home/vagrant/Projects/site4/public
- map: site5.localdev
to: /home/vagrant/Projects/site5/public
- map: site6.localdev
to: /home/vagrant/Projects/site6/public
- map: site7.localdev
to: /home/vagrant/Projects/site7/public
and they will all work. No need to add a corresponding hosts file entry for each web site. Just create your Laravel project at each of those directories.
Managing MySQL databases
I would recommend managing your databases by running software on your laptop that communicates with the MySQL server on the virtual machine. Personally I would use MySQL Workbench, but some people find HeidiSQL easier to use. HeidiSQL can manage PostgreSQL and Microsoft SQL databases too. You can connect via a forwarded port. If you wish to connect directly to the virtual machine, you’ll need to reconfigure MySQL in the virtual machine, as follows:
- Start the Git Bash prompt
- Open a shell on the virtual machine by issuing the command
vagrant ssh - Assuming you know how to use vi/vim, type
vim /etc/my.cnf. If you’re not familiar with vim, try nano, which displays help (keystrokes) at the bottom of the terminal:nano /etc/my.cnf - Look for the line
bind-address = 10.0.2.15and change it tobind-address = * - Save
my.cnfand exit the editor. - Issue the command
service mysql restart - You can now connect to MySQL using the VM’s normal MySQL port. Exit the shell with Ctrl-D or
exit.
Okay, okay, why go to all this trouble? I just prefer it. So sue me.
| Forwarded port | Direct to VM |
|---|---|
| Port: 33060 Host: 127.0.0.1 User name: homestead Password: secret |
Port: 3306 Host: 192.168.10.10 User name: homestead Password: secret |
Managing your environment
Each time you change the Homestead.yaml file, run the command vagrant provision from the Homestead directory, to push the changes through to the virtual machine. And once you’ve finished your development session, run vagrant suspend, to pause the virtual machine. (vagrant up starts it again.) If you want to tear the thing apart and start again, run the command vagrant destroy followed by vagrant up.






 UPDATE 2: WhatsApp has finally bowed to pressure and created a
UPDATE 2: WhatsApp has finally bowed to pressure and created a 

















 Are you? Is that you? Or are you like me and your
Are you? Is that you? Or are you like me and your