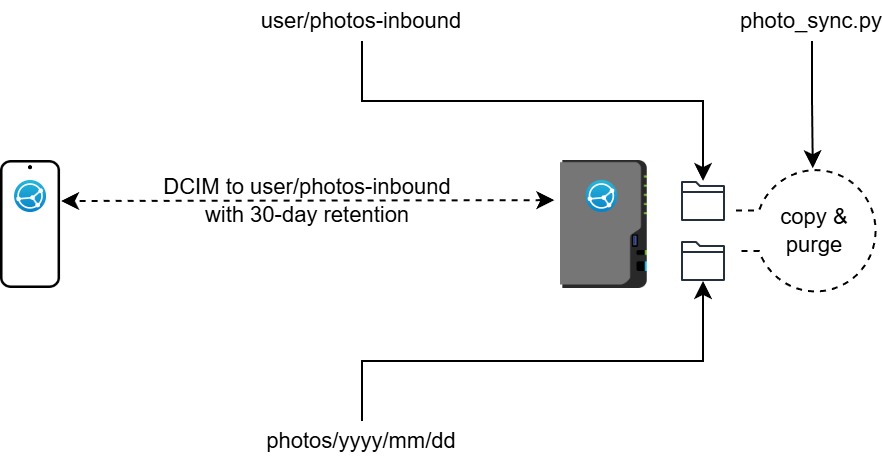
A wonderful little app disappeared from the Play Store recently: Sweet Home WiFi Picture Backup. This app perfectly (for me) synchronised my phone’s photos with my Synology NAS (via CIFS/SMB), creating the year/month/day filing I prefer, retaining photos on the phone for a specified period – in my case, one month.
Frustratingly there seems to be no other app that does exactly this. After much research and a bit of coding, I settled on the following:
Use Syncthing to synchronise my phone’s photos/videos to an interim holding area on my NAS.
Use a Python script to copy the media from that holding area to the permanent location in the year/month/day structure I prefer.
Allow the script to delete media from the holding area more than 30 days old. Syncthing propagates the deletions back to my phone.
Have the script use checksums (SHA1) to ensure that nothing is deleted unless it has been copied to the permanent location.
Use checksums also to ensure that no media is overwritten with different media of the same same.
On the NAS, use File Station to give the sc-syncthing group access to all folders that will be synced.
One on device add the other, within Syncthing
On the phone, share the DCIM folder, within Syncthing
On the NAS, set the target directory to (e.g.) a new folder photos-inbound in your user directory
Clone the photo_sync repository to your NAS, and ensure photo_sync.sh is executable
Set up the Python environment and install the necessary modules by running the following on the NAS (in a shell, in the folder containing the scripts):
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
deactivate
Copy the .env.example file to .env and edit the settings to suit you
Set a scheduled task to run photo_sync.sh as often as you require (I have it set to run daily at midnight)
See the code and the README in the GitHub repo for more details. Note that the Bash script activates the Python virtual environment and runs the Python script from within that environment.
If you’re running Visual Studio Code with WSL 2, you’ll find you get the best performance if your files are within the WSL filesystem. (I’ve written about this separately.)
You might still experience VS Code grinding to a halt, attempting to access files however. One symptom at this point is that if you run df or ls /mnt within WSL, this will hang. You may not even be able to exit with Ctrl-C or kill -9.
It seems that an I/0 lockup can occur with network/remote shares. One of the easiest ways to diagnose this is to strace df. This will show you the problematic share causing the hang. E.g.:
In my case I had the Windows W: drive connected to another Linux machine via, using SSHFS-Win. I don’t ever need to access this drive in WSL, but it’s available because I’m using automount.
To keep automount enabled, but exclude one network drive, for example:
Create an empty directory, which we’ll mount as a dummy: mkdir /mnt/empty
Ensure fstab mounting is enabled. In /etc/wsl.conf, in the [automount] section, you need a line: mountFsTab=true
Then in /etc/fstab, mount the folder that would normally be linked to the Windows drive to the empty folder instead. E.g.: /mnt/emptyW /mnt/w none bind 0 0
Restart WSL at a Windows command/terminal prompt: wsl --shutdown & wsl
The directory in question, that previously would have shown the contents of the remote folder, should now be empty.
If you have more than one such folder, you may need to repeat the steps, starting with strace df. For me, this restored VS Code’s filesystem performance.
Side note: sometimes the same symptoms can be caused by VPN connections. I’ve also seen performance issues mount up over time when I’ve had persistent OpenVPN connections running, either within WSL or in the Windows host.
In my development workflow (DevOps and scripting, mainly – I’m a security practitioner, not a programmer) I frequently switch between Windows and WSL. I work a lot with Ansible, and I love the fact that with WSL, I can enable full Ansible linting support in Visual Studio Code. The problem is that there are known cross-OS filesystem performance issues with WSL 2. At the moment, Microsoft recommends that if you require “Performance across OS file systems“, you should use WSL 1. Yuck.
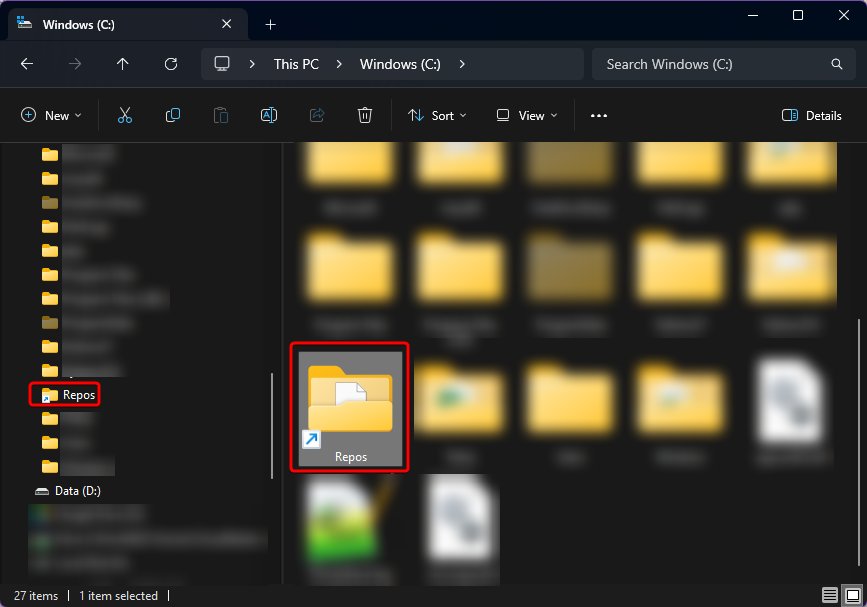
What I want to do is to have a folder on my Windows hard drive, C:\Repos, that contains all the repositories I use. I want that same folder to be available in WSL as the directory /repos. Network file shares are out of the question, because, performance. (Have you tried git operations on a CIFS share? Ugh.)
The old way – share from Windows to WSL
Until this week, I’d been sharing the Windows directory into WSL distros using /etc/fstab and automount options. Fstab contained this line:
But with this setup, every so often WSL filesystem operations would grind to a halt and I’d need to terminate and restart the distro. It could be minutes or days before the problem resurfaced.
The Windows Subsystem for Linux September 2023 update, currently available only for Windows Insider builds, was supposed to fix some of the issues. I tried it. The fixes broke Docker and didn’t improve filesystem performance sufficiently. Even after a Docker upgrade (the Docker folks in collaboration with the WSL team), port mapping remained broken.
The new way – share from WSL to Windows
So let’s fix this once and for all. Maybe the WSL filesystem perfomance issues will go away one day, but I need to get on with my work today, not at some unspecified point in the future. I also don’t like running insider builds, and neither did my endpoint protection software. (That’s another story.) In the meantime, we need to move the files into WSL, where the performance issues disappear. It’s cross-OS access that causes the problems.
Now I know about \\wsl.localhost, but unfortunately this confuses some of the programs I use day-to-day, including some VS Code plugins. I really need all Windows programs to believe and act like the files are on my hard drive.
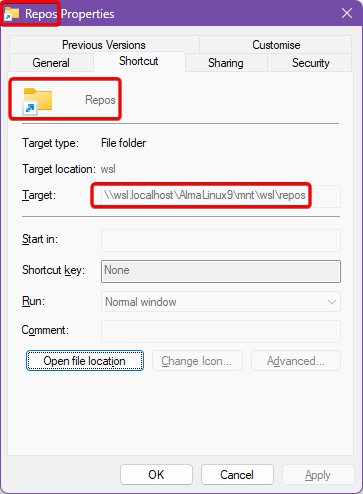
After much pulling together of information from dark, dusty corners of the internet, I discovered that, with the latest versions of Windows, you can create symbolic links to the WSL filesystem. So the files move into WSL (as /repos) and we create a symbolic link to that directory at C:\Repos. This can be as simple as uttering the following PowerShell incantation:
This should be fairly self-explanatory. In my case, I’m actually mapping to /mnt/wsl/repos, for reasons I’ll explain in the next section.
I have two VS Code workspaces – one for working directly in Windows, and the other for working in remote WSL mode. The Windows workspace points to C:\Repos and the WSL workspace points to /repos. When I restarted both workspaces after making these changes and moving the files into WSL, VS Code saw no difference. The files were still available, as before. But remote WSL operations now ran quicker.
Bonus: share folder with multiple distros
Ah, but what if you need the same folder to be available in more than one distribution? The same /repos folder in AlmaLinux, Oracle Linux and Ubuntu? Not network mapped? Is that even possible?
Absolutely it is. It’s possible through the expedient of mounting an additional virtual hard disk, which becomes available to all distros. This freaks me out slightly, because – what about file system locking? Deadlocks? Race conditions? Okay, calm down Rob, just exercise the discipline of only opening files within one distro at a time. You got this.
Create yourself a new VHDX file. I store mine in roughly the same place WSL stores all its VHDX files:
This gives you a raw, unformatted virtual hard drive at C:\Users\rob\AppData\Local\wsl\Repos.vhdx. Mount it within WSL. From the PowerShell session used above:
wsl --mount --vhd $DiskPath --bare
Now inside one of your distros, you’ll have a new drive, ready to be formatted to ext4. Easy enough to work out which device is the new drive – sort by timestamp:
ls -1t /dev/sd* | head -n 1
You’ll get something like /dev/sdd. Initialise this disk in WSL:
sudo mkfs -t ext4 /dev/sdd
(Do check you’re working with the correct drive – don’t just copy and paste!)
Back in the PowerShell session, we unmount the bare drive and remount it. WSL will automatically detect that the disk now contains a single ext4 partition and will mount that under /mnt/wsl – in all distros, mind you.
(shopt here ensures the move includes any hidden files with names begining ‘.‘.)
When sharing this directory into Windows, you need to use the full path /mnt/wsl/repos, not the symlink /repos. But otherwise it works the same as before.
This mount will not persist across reboots, so create a scheduled task to do this, that will run on log on.
For saying that I work in technology, I feel embarrassingly late to this party. I was recently transfixed by posts on Mastodon that showed images generated by Midjourney. I’d never heard of Midjourney. This started me off down a rabbit hole.
A few metres down the rabbit hole, I read about InvokeAI, an open-source alternative to Midjourney. A few metres more and I discovered that I would be able to run InvokeAI on my PC, which is equipped with an NVIDIA GeForce RTX 3060 graphics card.
That’s how I found myself installing and running InvokeAI, despite still knowing virtually nothing about any facet of AI, let alone image generation. Faced with the InvokeAI web interface, the first question becomes “What do all these knobs and buttons do? What are “CFG Scale”, “Sampler” and “Steps”? What is the difference between the “Models”?
In case you find yourself in the same position, here’s a handy guide.
What is Midjourney?
Midjourney is an independent research lab that produces a proprietary artificial intelligence program under the same name that creates images from textual prompts. It is powered by AI and machine learning algorithms and uses text prompts and parameters to generate images. It can be used for both creative and practical applications, such as creating custom artwork and logos, or visualising data. Midjourney is constantly learning and improving, and can be accessed through the Discord chat app by messaging the Midjourney Bot.
What is Stable Diffusion?
Stable Diffusion is an image-generating model developed by Stability AI. It is powered by artificial intelligence and machine learning algorithms, and uses text prompts and parameters to generate images. It can be used for both creative and practical applications, such as creating custom artwork and logos, or visualising data. Stable Diffusion is open-source, meaning anyone can access and use the model without cost. The model has a relatively good understanding of contemporary artistic styles, making it a popular choice for creative applications.
Stable Diffusion is based on the concept of a CFG Scale (see below), which is a mathematical representation of the complexity of a system, which can be used to analyze the behavior of the system over time. The CFG Scale is used to measure the stability of a system, which is an important factor in understanding how the system evolves over time.
The Stable Diffusion algorithm uses a “sampler” (see below) to collect data from the system at different points in time. The algorithm then uses a model to analyse the data collected from the sampler.
What’s InvokeAI then?
InvokeAI is an implementation of Stable Diffusion. It is powered by artificial intelligence and machine learning algorithms, and uses text prompts and parameters to generate images. It is optimised for efficiency, and can generate images with relatively low VRAM requirements. It supports the use of custom models.
The InvokeAI web interface offers lots of parameters. The rest of this article is dedicated to explaining those parameters.
InvokeAI‘s web interface
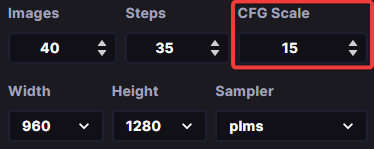
CFG Scale
The CFG Scale, or Classifier-Free Guidance Scale, is a parameter in the Stable Diffusion image generation model. It controls how much the image generation process is guided by the initial input, and how much it is random. (It determines the amount of noise in the generated image.) A high CFG Scale value produces output more closely resembling the text prompt.
The CFG Scale in InvokeAI’s web interface
A low CFG Scale value in Stable Diffusion can result in the output image having a lower fidelity and quality. It can for example lead to the model generating extra arms and legs! But it also increases the diversity and creativity of the result.
Increasing the CFG Scale value can result in higher quality, as well as a more dynamic colour range. It can also lead to more detailed images with a higher resolution. That said, high CFG values can lead to unrealistic-looking images.
The best CFG Scale value range for Stable Diffusion is generally between 7 and 11. Higher values of 50 to 100 are recommended for good outpainting results.
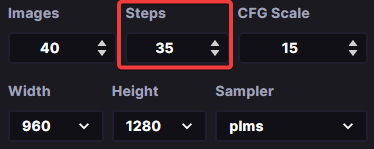
The Steps parameter
The Steps parameter of Stable Diffusion defines the number of inference steps used in the model. It dictates the amount of detail that is produced when generating images from text descriptions.
Steps parameter in InvokeAI’s web interface
Generally, increasing the number of steps will produce higher quality images, but this will come at the expense of slower inference. The optimal number of steps will depend on the dataset and task at hand. In most cases, images will converge on 30-50 steps and will not change significantly with higher steps.
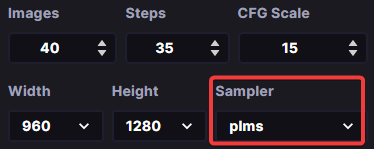
The Sampler parameter
InvokeAI provides several different samplers that can be used to generate samples from a given data distribution. The k_euler sampler uses the Euler-Maruyama algorithm to generate samples from a given distribution. The k_dmp_2 sampler uses a second-order differential equation to generate samples. Each of the samplers has its own advantages and disadvantages, and experimentation will be rewarded.
Sampler selection in InvokeAI’s web interface
The sampler is used to select regions of an image and generate a diffusion map that conditions the output of the model. The diffusion map is then used to generate a detailed image conditioned on text descriptions. The sampler also allows for a more efficient and stable training process, as it reduces the number of steps needed to generate a result. Additionally, the sampler can upscale samples from the diffusion model, allowing for better results when generating smaller images.
Prompts
Prompts in Stable Diffusion are phrases or words used to generate AI-generated images. They are used to provide the AI model with guidance on what type of image to create. Prompts can range from abstract concepts to specific objects or scenes. They can be weighted to emphasise certain keywords.
Example prompts include “a picture of a black cat on a kitchen top”, “Paintings of Landscapes”, “Style cue: Steampunk / Clockpunk”, “a beautiful sunset over a beach” or “a futuristic cityscape.” Using very specific prompts, helps the AI to generate more accurate and detailed images.
Different models*
Confusingly, you can use different models with InvokeIA. The most commonly used is the Stable Diffusion Model. InvokeAI can use a range of other models for image processing and manipulation tasks. InvokeAI also provides tools for creating custom models, allowing users to create their own models that can be used in combination with the existing models.
InvokeAI supports a variety of models, from classic Machine Learning algorithms such as Random Forest and Logistic Regression to deep learning models such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). The main differences between these models are the type of data that they process and the types of result they produce. For example, Random Forest and Logistic Regression are good at predicting classifications, while CNNs and RNNs are better at recognizing patterns in images and text. Additionally, CNNs and RNNs can be used for more complex tasks such as image recognition, text generation, and language translation.
Sneaky disclaimer
So here’s my disclaimer. I’ve pulled a slightly sneaky trick with this blog post. I’ve recruited AI to explain AI. That seemed logical. I used AI text generation services YouChat and Perplexity to explain Stable Diffusion, using prompts like “Explain the CFG Scale in Stable Diffusion.”
That feels like cheating. But I did at least sanity-check the results and edit them before posting here. Some of the answers were in fact wrong. And it was no quicker writing the blog post this way. But roughly 80% of the text in this blog post was AI-generated. How does that make you feel? Tell me in the comments!
*The AI-based text-generators really struggled to explain the difference between the various models that work with InvokeAI. My suggestion is to install some and experiment!
Note: I previously wrote about using plain PHP to query GitHub Projects V2. In this post I offer some tips for querying using Laravel.
GitHub’s new Projects are not accessible via the older REST API. Working with them programmatically involves learning some GraphQL, which can be a headache, the first time you encounter it. Here’s my approach, using Laravel.
GitHub’s new Projects are not accessible via the older REST API. Working with them programmatically involves learning some GraphQL, which can be a headache, the first time you encounter it. Here’s my approach, using PHP.
Set up cURL
You can certainly use an HTTP request library, but sometimes it’s easiest to get your hands dirty with cURL. Here’s the setup:
$ch = curl_init();
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPHEADER, array(
'Accept: application/vnd.github+json',
'Authorization: Bearer '.$_ENV['GH_TOKEN']
));
// Fake user agent, to keep GitHub happy
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 5.1; rv:31.0) Gecko/20100101 Firefox/31.0');
// Dev settings (PHP built-in server can't validate)
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
The “dev settings” are there since I’ve been using PHP’s built-in webserver during development. Don’t take those into production!
Generic API class
This class provides a simple wrapper around REST API and GraphQL calls. I’m passing in the cURL handler and calling most methods statically, since I’m not yet modelling the underlying objects.
class GitHub
{
/**
* API
* Make request to GitHub using the standard REST API.
* See: https://docs.github.com/en/rest
*
* @param [CurlHandle Object] $ch - curl handle
* @param [string] $endpoint - the REST endpoint
* @return array|stdClass
*/
public static function api(\CurlHandle $ch, string $endpoint)
{
curl_setopt($ch, CURLOPT_URL, 'https://api.github.com/'.$endpoint);
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');
$content = curl_exec($ch);
if (curl_errno($ch)) {
die("Error:".curl_error($ch));
}
return json_decode($content);
}
/**
* GraphQL
* Make request to GitHub using the newer GraphQL API.
* See: https://docs.github.com/en/graphql/reference
* GraphQL Explorer: https://docs.github.com/en/graphql/overview/explorer
* GraphQL Formatter: https://jsonformatter.org/graphql-formatter
*
* @param CurlHandle $ch
* @param string $query - a GraphQL query string
* @param array $variables - an array of GraphQL variables
* @return StdClass
*/
public static function graphQL(\CurlHandle $ch, string $query, array $variables)
{
curl_setopt($ch, CURLOPT_URL, 'https://api.github.com/graphql');
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'POST');
curl_setopt(
$ch,
CURLOPT_POSTFIELDS,
json_encode(['query' => $query, 'variables' => $variables])
);
$content = curl_exec($ch);
if (curl_errno($ch)) {
die("Error:".curl_error($ch));
}
return json_decode($content);
}
}
Projects class
Various simple methods for obtaining information about projects. I say “simple” but the GraphQL queries take some mastering.
class GitHubProjects
{
/**
* getFirstN - get first N projects for the GitHub organisation, ordered by
* title
*
* @param \CurlHandle $ch
* @param integer $count - number of projects to return
* @return array
*/
public static function getFirstN(\CurlHandle $ch, int $count = 20): array
{
$projects = GitHub::graphQL(
$ch,
<<<EOD
query getFirstN(\$count: Int) {
organization(login: "MyOrg") {
projectsV2(first: \$count, orderBy: {field: TITLE, direction: ASC}) {
nodes {
number
id
title
}
}
}
}
EOD,
[ "count" => $count ]
);
return $projects->data->organization->projectsV2->nodes;
}
/**
* getFirstNIssues
*
* @param \CurlHandle $ch
* @param integer $projectNumber
* @param integer $count
* @return array
*/
public static function getFirstNIssues(\CurlHandle $ch, int $projectNumber = 1, int $count = 20): array
{
$projectId = GitHubProjects::getIdByNumber($ch, $projectNumber);
$issues = GitHub::graphQL(
$ch,
<<<EOD
# Exclamation mark since projectId is required
query getFirstNIssues(\$projectId: ID!, \$count: Int) {
node(id: \$projectId) {
... on ProjectV2 {
items(first: \$count) {
nodes {
id
fieldValues(first: 8) {
nodes {
... on ProjectV2ItemFieldTextValue {
text
field {
... on ProjectV2FieldCommon {
name
}
}
}
... on ProjectV2ItemFieldDateValue {
date
field {
... on ProjectV2FieldCommon {
name
}
}
}
... on ProjectV2ItemFieldSingleSelectValue {
name
field {
... on ProjectV2FieldCommon {
name
}
}
}
}
}
content {
... on DraftIssue {
title
body
}
... on Issue {
title
assignees(first: 10) {
nodes {
login
}
}
}
... on PullRequest {
title
assignees(first: 10) {
nodes {
login
}
}
}
}
}
}
}
}
}
EOD,
[
"projectId" => $projectId,
"count" => $count
]
);
return $issues->data->node->items->nodes;
}
/**
* getByTitle - search for projects by title
*
* @param \CurlHandle $ch
* @param string $title - search for
* @return array
*/
public static function getByTitle(\CurlHandle $ch, string $title): array
{
$projects = GitHub::graphQL(
$ch,
<<<EOD
query getByName(\$title: String!) {
organization(login: "MyOrg") {
projectsV2(
first: 20
orderBy: { field: TITLE, direction: ASC }
query: \$title
) {
nodes {
number
id
title
}
}
}
}
EOD,
[ "title" => $title ]
);
return $projects->data->organization->projectsV2->nodes;
}
/**
* getIdByNumber
*
* @param \CurlHandle $ch
* @param integer $number - the integer identifier of the project
* @return string - the internal GitHub project ID (e.g. PVT_kwDOBWQiz84AH53W)
*/
private static function getIdByNumber(\CurlHandle $ch, int $number = 1)
{
$project = GitHub::graphQL(
$ch,
<<<EOD
# Exclamation mark since number is required
query getIdByNumber(\$number: Int!) {
organization(login: "MyOrg") {
projectV2(number: \$number) {
id
}
}
}
EOD,
['number' => $number]
);
return $project->data->organization->projectV2->id;
}
}
Using it
I have not included namespacing or autoloading here. In broad terms, it’s simple to use the Projects class:
This post is probably for pedants only, who care passionately about correctly sorting IP addresses in an Excel spreadsheet. This approach uses pure functions – no VBA. I prefer it to some other approaches because, frankly, they sail right over my head.
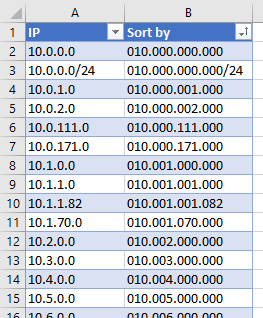
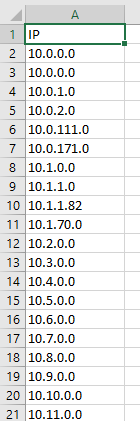
Let’s start with a column of IP addresses – like this one:
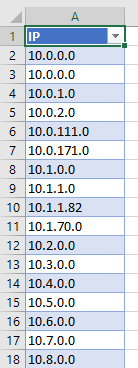
Excel tables are lovely, for working with data like this. If you convert your data to a table, you get to use named column references, which we’ll see in a moment. Go to Insert > Table and you get something like this:
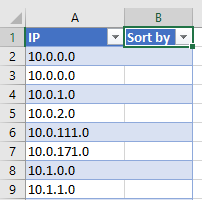
You can’t sort this column meaningfully, as-is. We need an additional column, which we’ll use to transform the contents of the IP column.
And then in any of the rows in that column, we enter this formula:
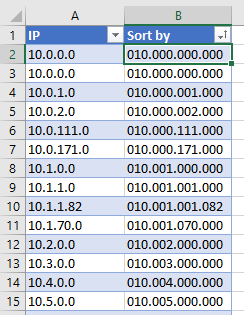
You end up with this, on which you can now perform an alphabetical (A-Z) sort:
If you like, you can hide that column, so you don’t need to look at its hideousness. Then whenever you need to resort, go to Data > Sort.
Some things to mention about this formula:
[@IP] is the named column reference I referred to previously.
I edited this formula in a code editor (Notepad++), so I could nicely indent and keep track of opened and closed parenthesis. This makes life much easier, when writing long formulae! There’s one gotcha – Notepad++ by default uses tabs rather than spaces, which breaks Excel. Make sure there are no tab characters in your indentation.
The IF(0,"##### THIRD OCTET #####","") stuff is a hack, which allows you to insert a comment into a text-based formula. The 0 evaluates to FALSE, so it returns the function’s third parameter – an empty string. The second parameter is where I place my comment. Handy!
Excel doesn’t have a function to find the position of the nth occurrence of a string. So there’s a nifty two-step hack for this, which is not my original idea. First, we use the SUBSTITUTE() function, which can substitute a character for the nth occurrence of some text. We search for the nth occurrence of the full stop (“.”) and replace it with CHAR(134) – the dagger symbol (†). Then we find the position of that CHAR(134), to feed into the LEFT()/MID()/RIGHT() functions.
Many people run free versions of ESXi, particularly in lab environments. Unfortunately with the free version of ESXi, the VMware API is read-only. This limits (or complicates) automation.
I was looking for a way to clone guest VMs with the minimum of effort. This script, which took inspiration from many sources on the internet, is the result. It takes advantage of the fact that although the API is limited, there are plenty of actions you can take via SSH, including calls to vim-cmd.
<#
.SYNOPSIS
Clones a VM,
.DESCRIPTION
This script:
- Retrieves a list of VMs attached to the host
- Enables the user to choose which VM to clone
- Clones the VM
It must be run on a Windows machine that can connect to the virtual host.
This depends on the Posh-SSH and PowerCLI modules, so from an elevated
PowerShell prompt, run:
Install-Module PoSH-SSH
Install-Module VMware.PowerCLI
For free ESXi, the VMware API is read-only. That limits what we can do with
PowerCLI. Instead, we run certain commands through SSH. You will therefore
need to enable SSH on the ESXi host before running this script.
The script only handles simple hosts with datastores under /vmfs. And it
clones to the same datastore as the donor VM. Your setup and requirements
may be more complex. Adjust the script to suit.
.EXAMPLE
From a PowerShell prompt:
.\New-GuestClone.ps1 -ESXiHost 192.168.101.100
.COMPONENT
VMware scripts
.NOTES
This release:
Version: 1.0
Date: 8 July 2021
Author: Rob Pomeroy
Version history:
1.0 - 8 July 2021 - first release
#>
param
(
[Parameter(Mandatory = $true, Position = 0)][String]$ESXiHost
)
####################
## INITIALISATION ##
####################
# Load necessary modules
Write-Host Loading PowerShell modules...
Import-Module PoSH-SSH
Import-Module VMware.PowerCLI
# Change to the directory where this script is running
Push-Location -Path ([System.IO.Path]::GetDirectoryName($PSCommandPath))
#################
## CREDENTIALS ##
#################
# Check for the creds directory; create it if it doesn't exist
If(-not (Test-Path -Path '.\creds' -PathType Container)) {
New-Item -Path '.\creds' -ItemType Directory | Out-Null
}
# Looks for credentials file for the VMware host. Passwords are stored encrypted
# and will only work for the user and machine on which they're stored.
$credsFile = ('.\creds\' + $ESXiHost + '.creds')
If(-not (Test-Path -Path $credsFile)) {
# Request credentials
$creds = Get-Credential -Message "Enter root password for VMware host $ESXiHost" -User root
$creds.Password | ConvertFrom-SecureString | Set-Content $credsFile
}
$ESXICredential = New-Object System.Management.Automation.PSCredential( `
"root", `
(Get-Content $credsFile | ConvertTo-SecureString)
)
#########################
## List VMs (PowerCLI) ##
#########################
#
# Disable HTTPS certificate check (not strictly needed if you use -Force) in
# later calls.
Set-PowerCLIConfiguration -InvalidCertificateAction Ignore -Confirm:$false | Out-Null
# Connect to the ESXi server
Connect-VIServer -Server $ESXiHost -Protocol https -Credential $ESXICredential -Force | Out-Null
If(-not $?) {
Throw "Connection to ESXi failed. If password issue, delete $credsFile and try again."
}
# Get all VMs, sorted by name
$guests = (Get-VM -Server $ESXiHost | Sort-Object)
# Work out how much we need to left-pad the array index, when outputting
$padWidth = ([string]($guests.Count - 1)).Length
# Output the list of VMs, with array index padded so it lines up nicely
Write-Host ("Existing VMs (" + $guests.Count + "), sorted by name:")
for ( $i = 0; $i -lt $guests.count; $i++)
{
If($guests[$i].PowerState -eq "PoweredOn") {
Write-Host -ForegroundColor Red ("[" + "$i".PadLeft($padWidth, ' ') + "](ON) : " + $guests[$i].Name)
} Else {
Write-Host ("[" + "$i".PadLeft($padWidth, ' ') + "](off): " + $guests[$i].Name)
}
}
Write-Host
##########################
## Choose a VM to clone ##
##########################
$chosenVM = 0
do {
$inputValid = [int]::TryParse((Read-Host 'Enter the [number] of the VM to clone (the donor)'), [ref]$chosenVM)
if($chosenVM -lt 0 -or $chosenVM -ge $guests.Count) {
$inputValid = $false
}
if (-not $inputValid) {
Write-Host ("Must be a number in the range 0 to " + ($guests.Count - 1).ToString() + ". Try again.")
}
} while (-not $inputValid)
# Check the VM is powered off
if($guests[$chosenVM].PowerState -ne "PoweredOff") {
Throw "ERROR: VM must be powered off before cloning"
}
# Get VM's datastore, directory and VMX; we assume this is at /vmfs/volumes
If(-not ($guests[$chosenVM].ExtensionData.Config.Files.VmPathName -match '\[(.*)\] ([^\/]*)\/(.*)')) {
Throw "ERROR: Could not calculate the datastore"
}
$VMdatastore = $Matches[1]
$VMdirectory = $Matches[2]
$VMXlocation = ("/vmfs/volumes/" + $VMdatastore + "/" + $VMdirectory + "/" + $Matches[3])
$VMdisks = $guests[$chosenVM] | Get-HardDisk
###############################
## File test (PoSH-SSH SFTP) ##
###############################
# Clear any open SFTP sessions
Get-SFTPSession | Remove-SFTPSession | Out-Null
# Start a new SFTP session
(New-SFTPSession -Computername $ESXiHost -Credential $ESXICredential -Acceptkey -Force -WarningAction SilentlyContinue) | Out-Null
# Test that we can locate the VMX file
If(-not (Test-SFTPPath -SessionId 0 -Path $VMXlocation)) {
Throw "ERROR: Cannot find donor VM's VMX file"
}
#################
## New VM name ##
#################
$validInput = $false
While(-not $validInput) {
$newVMname = Read-Host "Enter the name of the new VM"
$newVMdirectory = ("/vmfs/volumes/" + $VMdatastore + "/" + $newVMname)
# Check if the directory already exists
If(Test-SFTPPath -SessionId 0 -Path $newVMdirectory) {
$ynTest = $false
While(-not $ynTest) {
$yn = (Read-Host "A directory already exists with that name. Continue? [Y/N]").ToUpper()
if (($yn -ne 'Y') -and ($yn -ne 'N')) {
Write-Host "ERROR: enter Y or N"
} else {
$ynTest = $true
}
}
if($yn -eq 'Y') {
$validInput = $true
} else {
Write-Host "You will need to choose a different VM name."
}
} else {
If($newVMdirectory.Length -lt 1) {
Write-Host "ERROR: enter a name"
} else {
$validInput = $true
# Create the directory
New-SFTPItem -SessionId 0 -Path $newVMdirectory -ItemType Directory | Out-Null
}
}
}
###################################
## Copy & transform the VMX file ##
###################################
# Clear all previous SSH sessions
Get-SSHSession | Remove-SSHSession | Out-Null
# Connect via SSH to the VMware host
(New-SSHSession -Computername $ESXiHost -Credential $ESXICredential -Acceptkey -Force -WarningAction SilentlyContinue) | Out-Null
# Replace VM name in new VMX file
Write-Host "Cloning the VMX file..."
$newVMXlocation = $newVMdirectory + '/' + $newVMname + '.vmx'
$command = ('sed -e "s/' + $VMdirectory + '/' + $newVMname + '/g" "' + $VMXlocation + '" > "' + $newVMXlocation + '"')
($commandResult = Invoke-SSHCommand -Index 0 -Command $command) | Out-Null
# Set the display name correctly (might be wrong if donor VM name didn't match directory name)
$find = 'displayName \= ".*"'
$replace = 'displayName = "' + $newVMname + '"'
$command = ("sed -i 's/$find/$replace/' '$newVMXlocation'")
($commandResult = Invoke-SSHCommand -Index 0 -Command $command) | Out-Null
# Blank the MAC address for adapter 1
$find = 'ethernet0.generatedAddress \= ".*"'
$replace = 'ethernet0.generatedAddress = ""'
$command = ("sed -i 's/$find/$replace/' '$newVMXlocation'")
($commandResult = Invoke-SSHCommand -Index 0 -Command $command) | Out-Null
#####################
## Clone the VMDKs ##
#####################
Write-Host "Please be patient while cloning disks. This can take some time!"
foreach($VMdisk in $VMdisks) {
# Extract the filename
$VMdisk.Filename -match "([^/]*\.vmdk)" | Out-Null
$oldDisk = ("/vmfs/volumes/" + $VMdatastore + "/" + $VMdirectory + "/" + $Matches[1])
$newDisk = ($newVMdirectory + "/" + ($Matches[1] -replace $VMdirectory, $newVMname))
# Clone the disk
$command = ('/bin/vmkfstools -i "' + $oldDisk + '" -d thin "' + $newDisk + '"')
Write-Host "Cloning disk $oldDisk to $newDisk with command:"
Write-Host $command
# Set a timeout of 10 minutes/600 seconds for the disk to clone
($commandResult = Invoke-SSHCommand -Index 0 -Command $command -TimeOut 600) | Out-Null
#Write-Host $commandResult.Output
}
########################
## Register the clone ##
########################
Write-Host "Registering the clone..."
$command = ('vim-cmd solo/register "' + $newVMXlocation + '"')
($commandResult = Invoke-SSHCommand -Index 0 -Command $command) | Out-Null
#Write-Host $commandResult.Output
##########
## TIDY ##
##########
# Close all connections to the ESXi host
Disconnect-VIServer -Server $ESXiHost -Force -Confirm:$false
Get-SSHSession | Remove-SSHSession | Out-Null
Get-SFTPSession | Remove-SFTPSession | Out-Null
# Return to previous directory
Pop-Location
At the time of writing, the excellent EOS 90D is the modern equivalent of my 60D. I really want a Sony Alpha though! In the interests of transparency: these are affiliate links. See my affiliate disclosure page for an explanation.
Necessity is the mother of invention. In the midst of the trauma and struggles of coronavirus, one positive theme has consistently emerged: innovation. In particular, the explosive rise of home working, podcasting and vlogging has resulted in significant improvements in associated technology.
So when I recently started researching ways to raise my webcam game (for conference calls and church meetings), I was spoilt for choice. Since I’m a fan of both cost-efficiency and quality, I was particularly interested in seeing what could be achieved with my existing equipment, including my faithful DSLR camera – a Canon EOS 60D.
The last time I looked into this, the main way to take a feed from this camera model, was through its HDMI port and a separate video capture device (which I don’t own). But Canon has pulled an innovation blinder, releasing and improving its EOS Webcam Utility and ensuring that it not only works with the latest hardware, but also with such aging models as my ten-year-old 60D. Oh Canon, I love you.
“There must be a catch,” I thought, as I read reports of camera sensors overheating, or timing out after 30 minutes. So with no great expectations, I downloaded and tested the software.
Oh. My. Word. Did I mention Canon how I love you?
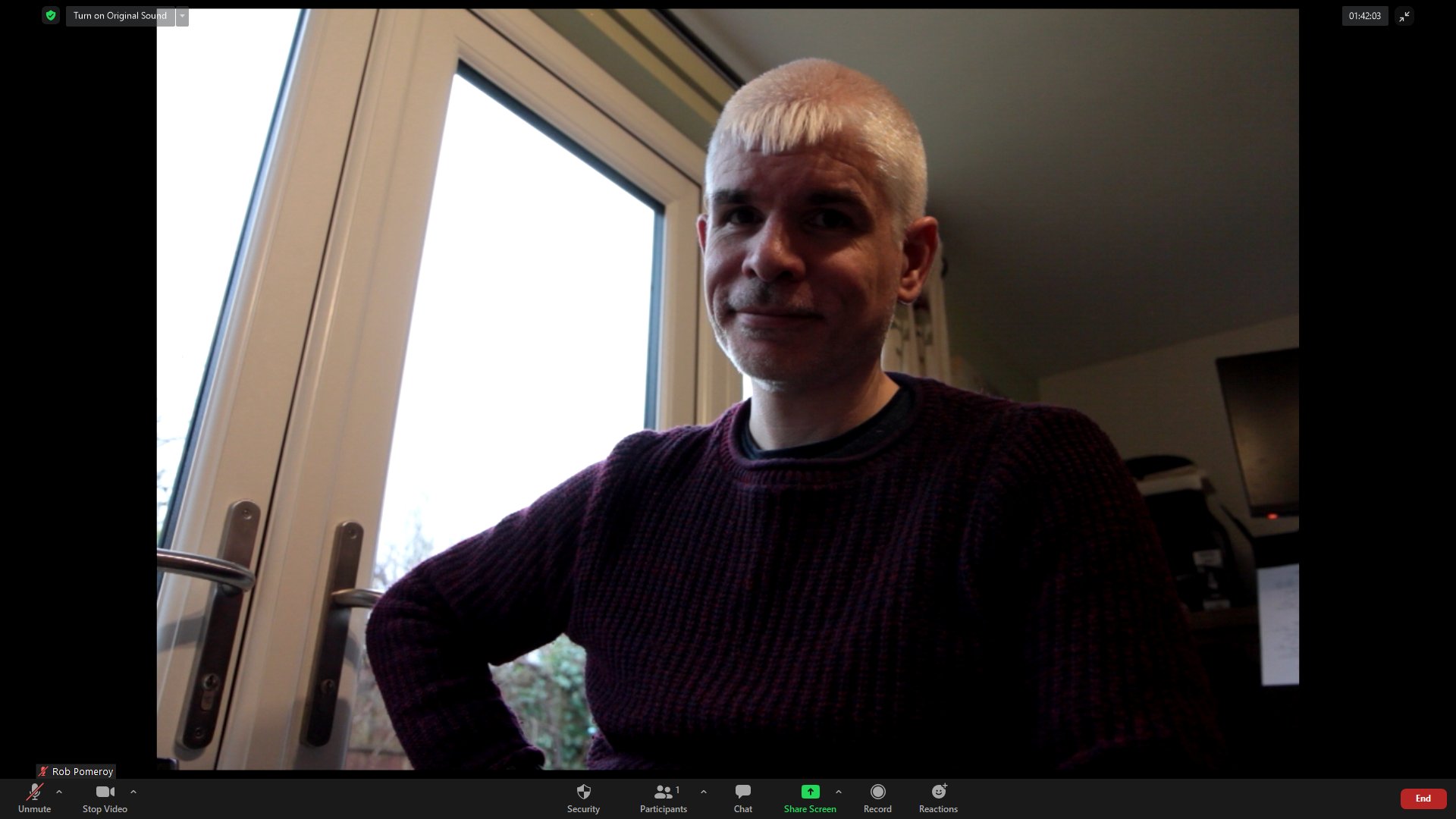
Screenshot of a Zoom session using the EOS webcam utility, my Canon EOS 60D and a 17-55 f/2.8 lens.
With zero effort and no tweaking of camera settings, the improvement was immediately visible. From the screenshot you can see I need to work on contrast and lighting. But for a first test, this made me very happy.
Did the camera overheat or timeout? No. I ran the session for about two hours. The camera was slightly warm at the end. Granted it’s not a hot summer’s day here in the UK (is it ever!) but it looks to me like this setup would work all day, every day. The only snag is battery life. So instead of being on the market for a superior webcam, I’m instead on the market for an external power supply (like Canon’s ACK-E6). Clones of the OEM adapter are available for about £23. Bargain.
If you’re reading this page, you probably already have an MFA strategy sorted. But for those still making decisions: I love my YubiKey 5 NFC. I use it constantly to log into AWS, to secure my GitHub account, to protect my “I would be completely ruined if it were hacked” email account, etc. My wife was extremely puzzled when I asked for one for my birthday. She didn’t really know what it was she was buying me. What a great present though!
In the interests of transparency: this is an affiliate link. See my affiliate disclosure page for an explanation.
AWS has a tutorial about enforcing MFA for all users. The general thrust of the article is to create a policy that allows users without MFA to do nothing other than log in and set up MFA. Having enabled and logged in using MFA, other permissions become available to the user (according to whatever other permissions are assigned).
This works well apart from one snag: having created a user, and set the flag forcing the user to change password on first login, the user cannot log in. Instead the user is greeted with the following error:
Either user is not authorized to perform iam:ChangePassword or entered password does not comply with account password policy set by administrator
The problem lies in a policy statement called “DenyAllExceptListedIfNoMFA”. As its name suggests, for a user without MFA, this blocks all bar the specified actions. In AWS’s recommended policy, the section effectively allows the following actions:
You’ll notice that those actions don’t include anything about changing a password! So without MFA already enabled on your account, there’s no way to change your password when first logging on (if “force password change” is enabled). The trick is to add two more permissions:
"iam:ChangePassword",
"iam:CreateLoginProfile",
For a user that has not yet logged into the AWS console, this will allow creation of the user’s login profile and setting a new password.
This website uses cookies to improve your experience. I will assume you're ok with this, but you can opt-out if you wish.AcceptRejectRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.
















{kind=link}