There isn’t yet an official Ansible module for managing Windows Defender exclusions. If you’re committed to idempotency, and not sure how to add a path to Windows Defender’s exclusions list, read on!
I’ll get straight into the task:
- name: Exclude directories from Windows Defender
ansible.windows.win_powershell:
script: |
$Ansible.Changed = $false
# Check if the folder is already excluded
$excluded = Get-MpPreference | Select-Object -ExpandProperty ExclusionPath | Where-Object { $_ -eq "{{ item }}" }
if ($null -eq $excluded) {
# Add the folder to the exclusion list
try {
Add-MpPreference -ExclusionPath "{{ item }}"
$Ansible.Changed = $true
} catch {
$Ansible.Failed = $true
}
}
loop:
- C:\foo\bar.exe
- H:\baz\qux
To break it down:
loop: Pass the file/directory paths that you wish to exclude, as a list. Add-MpPreference does not accept wildcards, so you may need to be verbose, or add exclusions at the directory level rather than file level. These are the “target exclusions” referred to below.
ansible.windows.win_powershell: This module gives us the ability with custom PowerShell scripts to tell Ansible explicitly whether the task failed or resulted in a change.
$Ansible.Changed = $false: Ansible uses this variable to detect whether or not the task resulted in a change. We initialise it to $false, since no change has occurred yet.
Get-MpPreference: This PowerShell cmdlet retrieves lots of Windows Defender configuration imformation.
Select-Object -ExpandProperty ExclusionPath: Get the existing exclusions from the previous command, as a list.
Where-Object { $_ -eq "{{ item }}" }: Look for our target exclusion in the list.
if ($null -eq $excluded) {: If we didn’t find the target exclusion, run the next bit of code. If we did find the exclusion, we don’t execute any more code. the script will end with $Ansible.Changed still set to $false, which is what we want, to preserve idempotency.
try { ... } catch { ... }: If we fail to add the exclusion, PowerShell throws an error, so we wrap this in try..catch so we can handle that failure.
Add-MpPreference -ExclusionPath "{{ item }}": Add the target exclusion to Windows Defender’s exclusions list. Note that if this fails, PowerShell will immediately jump to the code in the catch block.
$Ansible.Changed = $true: We’ll only reach this line if (a) the target exclusion wasn’t already in the list and (b) adding the exclusion succeeded. Hence we set $Ansible.Changed to $true.
$Ansible.Failed = $true: We reach this code if Add-MpPreference failed, hence we set $Ansible.Failed to $true.
I hope this is helpful! If you know of a better or more elegant way of doing this, let me know in the comments. 🙂
If you’re reading this page, you probably already have an MFA strategy sorted. But for those still making decisions: I love my YubiKey 5 NFC. I use it constantly to log into AWS, to secure my GitHub account, to protect my “I would be completely ruined if it were hacked” email account, etc. My wife was extremely puzzled when I asked for one for my birthday. She didn’t really know what it was she was buying me. What a great present though!
In the interests of transparency: this is an affiliate link. See my affiliate disclosure page for an explanation.
AWS has a tutorial about enforcing MFA for all users. The general thrust of the article is to create a policy that allows users without MFA to do nothing other than log in and set up MFA. Having enabled and logged in using MFA, other permissions become available to the user (according to whatever other permissions are assigned).
This works well apart from one snag: having created a user, and set the flag forcing the user to change password on first login, the user cannot log in. Instead the user is greeted with the following error:
Either user is not authorized to perform iam:ChangePassword or entered password does not comply with account password policy set by administrator
The problem lies in a policy statement called “DenyAllExceptListedIfNoMFA”. As its name suggests, for a user without MFA, this blocks all bar the specified actions. In AWS’s recommended policy, the section effectively allows the following actions:
You’ll notice that those actions don’t include anything about changing a password! So without MFA already enabled on your account, there’s no way to change your password when first logging on (if “force password change” is enabled). The trick is to add two more permissions:
"iam:ChangePassword",
"iam:CreateLoginProfile",
For a user that has not yet logged into the AWS console, this will allow creation of the user’s login profile and setting a new password.
There’s something better than a risk matrix? It’s a bold claim. But risk matrices have significant weaknesses, as I have discussed elsewhere.
In information security, we know (I hope) that our role is primarily concerned with the control of risk. We may agree that’s what we’re doing – but unless we can measure risk and show how our efforts change our risk exposure, where’s our credibility?
When suggesting we should measure risk in infosec, a common objection is that we can’t measure this – there are too many unknowns. But we do ourselves a disservice here: we know a lot. We’ve trained, we have experience. And much as I hate to use the term, we’re experts. (Certainly when compared to people outside our field.)
So we take our expert opinions, maybe some historical data and we feed it into a model. ‘Modelling’ can be an intimidating concept until we understand what we mean. We model all the time – tabletop DR exercises, threat modelling, run books, KPI projections. The point is once we know what we’re doing, it’s not intimidating at all.
So let’s get over that hump.
Risk modelling is a matter of statistics. Again, don’t let that put you off. You don’t need to be a stats whizz to use a statistical model. Many of us are engineers. We know how to use tools; we like using tools; we often make our own tools. Statistical models are simply tools; we just need to learn how to use them. We don’t necessarily need to be able to derive them. But usually we like to have some idea of what’s going on ‘under the hood’. So here’s a whistle-stop tour of the concepts underpinning the model I present below.
Distributions
Let’s say we’re finding out how many televisions there are in the households in our city. We take a poll, where each household reports how many televisions they have and then we plot a graph. The x-axis shows number of televisions, say from one to ten. The y-axis shows number of households with that number of televisions.
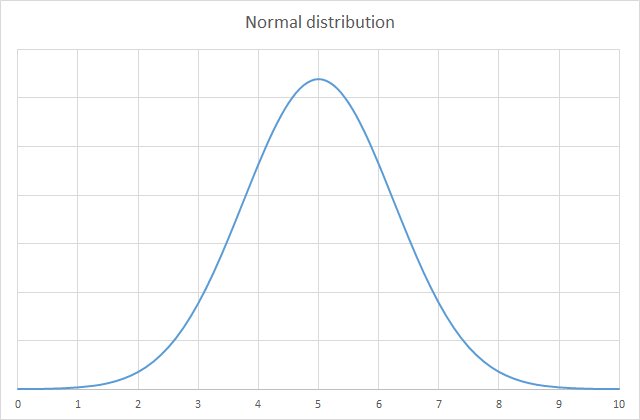
We might expect to see a graph a bit like this (yeah, that’s a lot of televisions):
This is a normal distribution. Normal distributions are common in statistics and produce a curve that’s often called a ‘bell curve’, due to its shape. The data tends to congregate around a central point, with roughly equal values either side. The amount of spread is called the ‘standard deviation’.
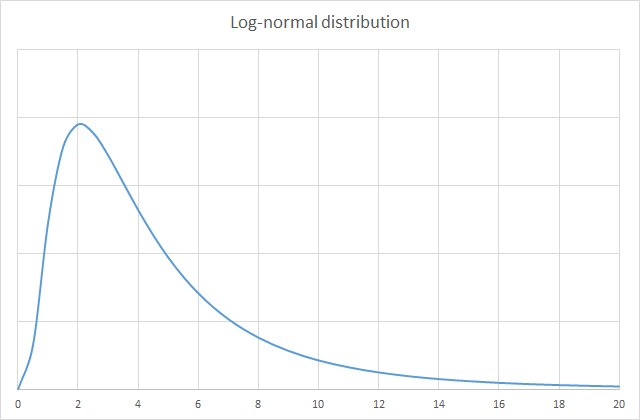
Reality often shapes itself into a normal distribution. But in information security risk, you may find that other types of distribution better reflect the circumstances. One such option is the log-normal distribution. Here’s its curve:
If we’re measuring the impact of an event, a log-normal distribution often fits the bill. It does not go below zero (an impact by definition means an above-zero loss). The values tend to congregate toward the left of the graph, but it leaves open the option for a low probability of a very high number, to the right of the graph.
What we’re doing is creating a mathematical/statistical model of reality. Since it’s a model, we choose whatever tool works best. A log-normal distribution is a good starting point.
Confidence interval
In measuring risk, we take account of our uncertainty. If we were in the enviable position of having absolute certainty about future events, we would be better off turning this astonishing talent to gambling. As it is, we’re not sure about the likelihood and impact of detrimental events, and hence we estimate.
When estimating impact, we could simply select a value from one to five and produce a risk matrix. But as we saw before, this is not particularly informative and in fact it can be misleading. One aspect that the ordinal scoring overlooks is that impact is best expressed as a range. If the negative event occurs, e.g. we experience a ransomware outbreak, that may prove to be a low-impact incident, or things may go horribly wrong and it costs us millions.
The confidence interval allows us to express a range for the impact, based on our level of uncertainty.
A confidence interval of 90% is often used. This means that the actual impact has a 5% chance of being above this range and a 5% chance of being below the range. In practice this proves to be good enough for our purposes.
Side-note: the log-normal curve that models a 90% confidence interval has a standard deviation of 3.29. We’ll use this fact shortly.
Imagine you have ten identical slips of paper. On nine of them, you write ‘winner’; on the other one, you write ‘loser’. All ten slips are placed into a hat and you draw one out at random. If you draw the ‘winner’ slip, you win £1,000. Otherwise, you win nothing.
On the other hand, there is a football match coming up today and your favourite team is playing. You are asked to predict the likely number of goals your team will score, within a range, with 90% confidence (nine in ten). Again, if you are right, you win £1,000.
In the book How to Measure Anything in Cybersecurity Risk, the authors call this an ‘equivalent bet’ test. If you prefer the idea of drawing slips out of a hat, because you think you’re more likely to win, that means you didn’t really use a 90% confidence interval for the football score prediction. You need to widen the range.
On the other hand, if you prefer the football bet, that means that your range prediction was probably too wide. You’ve used perhaps a 95% confidence interval.
The trick is to balance the two such that the potential reward is equivalent in either scenario. In this way, you will have achieved a true 90% C.I. with your football prediction. It takes a little effort to wrap your head around this but press on: this is an invaluable concept in risk analysis, which we’ll use shortly.
Estimating likelihood
When you’ve defined your threat event, estimating its likelihood is straightforward: define a time period and a probability (percentage likelihood) of the event occurring. To be meaningful, don’t make the event too specific. So ‘a ransomware outbreak’ is probably a better event definition for most companies than ‘a solar flare causing communications anomalies that disrupt global networking such that intercontinental backups are delayed by three hours’.
Over a 12-month period, you may estimate that you have a 5% likelihood of experiencing a ransomware outbreak. This percentage need be no more than the considered opinion of one or more experts. You can improve the estimation through the use of data: historical ransomware attacks in your sector, global threat activity, etc. But the data is no more required for this model than it was for a traditional risk matrix.
At this stage, do not consider the severity of the attack, just the likelihood. This likelihood percentage stands in the place of the 1 to 5 numbering in the risk matrix; it is simply more helpful.
Estimating impact
For impact, you now estimate a range, using a 90% confidence interval. You can use the equivalent bet test if you like, to guide your estimate. Again, you can take into account any available data, including known costs of breaches as they are reported worldwide. You can also consider things like the possible duration of an outage, the costs associated to an outage, the costs of paying the ransom or the excess on a cyber risk insurance policy. So you might say, all things considered, you are 90% confident that the impact would be between £250k and £1.5m.
We’re going to use a log-normal distribution, as shown above. During modelling, due to the long tail on this graph, you may find that the model produces some extremely high values that are simply not realistic (£75m, say) – unrealistic for whatever reason, such as the fact perhaps this exceeds your company’s annual global sales. You can therefore introduce a cap to this impact; e.g. a 90% C.I. of £250k to £1.5m, capped at £10m.
Modelling the risk
You now have all the data you need, to model the risk. What does this mean? Merely that you will insert these numbers into a formula and find out what happens when you run the formula a thousand, ten thousand, a hundred thousand times.
And why will you see different answers each time you apply the formula? Because we introduce two random variables. The random variables are based on all the above. The first random variable represents whether the event occurred ‘this year’, based the likelihood probability. To express this as a formula in Excel, Google Sheets or >insert favourite spreadsheet editor here< you do:
= IF (RAND() > likelihood, 0, 1)
Here, likelihood is the percentage expressed as a decimal (0.05). And RAND() produces a decimal number less than 1. So if RAND() is greater than 5%, the event didn’t occur and the result is 0. If RAND() is less than 5%, it did occur, hence the result is 1. We will multiply this by the impact, which we calculate next.
For impact, we use an inverse log-normal function. We chose to use a log-normal distribution above, we know the impact is somewhere within that distribution and again we use RAND() to work out the precise impact (‘this time’) based on this knowledge. Remember that with a 90% CI, there’s a 5% chance the impact will be higher or lower than the range we specified. And remember further that 3.29 is the standard deviation for such a curve.
So we have the range and the confidence interval and we’re working back to a single figure. The formula is this:
= LOGNORMAL.INV(RAND(), mean, standard deviation)
Or, where high and low represent the upper and lower bounds:
Use LOGNORMAL.INV in Excel. In Google Sheets the function is LOGNORM.INV. With log-normal distributions, the figures are based on the log of the mean and standard deviation – that’s why you see here the log function LN.
To prove that you don’t need fancy software or a powerful computer to do this modelling, I ran this simulation using Google Sheets on a modestly-specced Chromebook, over 1,000 rounds. You can download the spreadsheet at the end of this article to see how this worked. To cut a long story short, on one run of this simulation I ended up with the figure £45,540.19, being the annual risk exposure for this threat. (With just 1,000 rounds, you can expect to see some variation each time you recalculate, but it’s enough to demonstrate the model.)
You’ll see in the spreadsheet some columns mysteriously labelled “Loss Exceedance Calculations”. At some point, I may write an article to address that!
For now, I hope this has whetted your appetite and given you enough to start improving upon your risk matrices. Happy modelling! And if you’re interested in learning a bit more about statistics in general (some measure of stats fluency is well worth it), I suggest taking a look at Statistics for Dummies. Don’t be put off by the title!
As a security professional, unless you work for an MSSP (Managed Security Service Provider), security is simply a cost to the business. Fitting a swipe card door entry system will not in itself generate more revenue. Increased password complexity rules are unlikely to result in increased sales.
How then do we justify our existence? By the way we reduce risk.
If you work in penetration testing or you’re a network security engineer, you might find this to be a very unsexy subject. Risk. Boring. But it underpins everything you do and should be at the heart of every choice you make. We do not secure our networks simply because the manual says we should, or because the compliance department insists on it; we do it because it reduces risk. In reducing risk, we’re improving stability, longevity, our ability to service our customers; in short, we’re protecting our jobs.
Well then. How do you know if your actions as a pen tester or engineer reduce risk? Through risk assessments. Stay with me.
You may already have been subject to a risk assessment in your workplace – checking you know how to use your office chair, for example. And if this is your only experience of risk assessment, I can understand why you might be completely put off by the whole thing.
But there’s more to it than that. And risk assessment in information security can be a lot more interesting (and less patronising). Truly. I’m an engineer by disposition and yet I’m excited about risk.
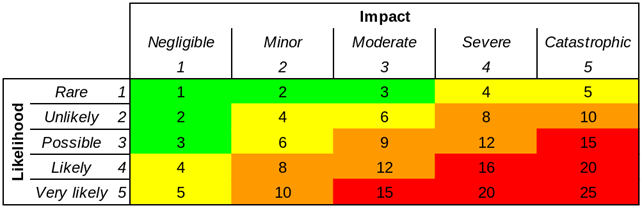
Now if you’ve been around for any length of time, you’ve no doubt seen one of these, the humble risk matrix:
On the face of this, a risk matrix couldn’t be easier to understand. (Perhaps that’s why we like them.) For any given risk, figure out the likelihood of it occurring (on a scale from one to five) and also the consequence, again on a scale of one to five. You can now position this risk on the matrix. And hey, maybe even multiply those two numbers together, to give you a single overall risk figure. Why not. Likelihood 4, consequence 5, okay that’s a risk of 20. Simple.
But what do we mean by ’20’? What do you mean? What does your CEO mean? Is it an absolute number? Or relative? Is a 20 twice as bad as a 10? The fact is that different people can have completely different perspectives on the meaning of these figures. We only have the illusion of communication. We’re using ordinal numbers, not cardinals.
A five by five risk matrix is an example of qualitative (as opposed to quantitative) risk analysis. A relatively arbitrary value is assigned on the basis of a subjective view of a risk.
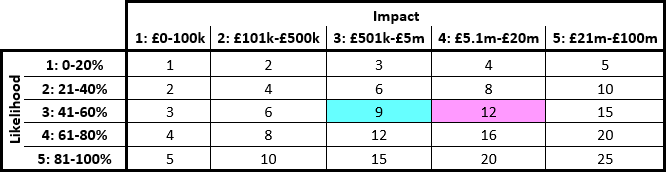
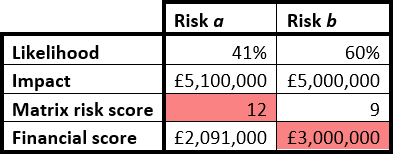
Some organisations partially overcome the limitations of this approach by assigning explicit values to different ranks in the risk matrix. The likelihood can be split into five bands of 20% each, for example. Financial values are applied to impact. This is semi-quantitative analysis. E.g.:
Such divisions can also be misleading, unfortunately. Consider:
A 41% likelihood (3) of a £5.1m impact (4) would be scored as 12.
A 60% likelihood (3) of a £5m impact (3) would be scored as 9.
In this risk matrix analysis, risk a seems to be more severe than risk b. But consider the probability calculations:
A 41% likelihood of a £5.1m impact gives financial exposure of £2,091,000.
A 60% likelihood of a £5m impact gives financial exposure of £3,000,000.
So the risk matrix shows a to be the higher risk, but the calculation shows b to be higher. Both can’t be correct. Using a probability scale combined with likelihood range slices demonstrably results in incorrect prioritisation. (And a lack of these clarifying measures must inevitably result in even less reliable ‘calculations’.)
This may seem like a trivial example, but this could be the difference between a project being approved or postponed – on the basis of faulty analysis. And if that project is life-or-death – which it might be, in military or healthcare applications – then the risk matrix could indeed kill you*.
I’ll leave it on that bombshell – in later posts I will discuss some alternatives.
Are you interested in the forensic side of information security? Want to hone your pen testing skills but not sure where to start? Heard of reverse engineering, but it seems like a black art?
This article is a link dump (so it might go out of date, sorry) of free tools and resources to help you along the way. It started from an email I sent to a security analyst who was interested in learning more about this field.
My interests lie more in cybersecurity risk and management, rather than this low-level, detail-orientated stuff. Yes, that is my way of saying, “No way would I be good enough to reverse engineer malware.” But if I were going to get into this field, this is where I would start.
Feel free to suggest further links in the comments!
Capture
The Flag
CTFs are intended to be a fun way to improve
your forensic and testing skills.
Those who know me well have probably heard me grumbling about IoT devices – things like Nest, Google Homehub, Amazon Echo, etc. 🙂 That’s for a very good reason – you are surrendering your privacy and opening your home up to potential cyber invasion.
There’s a lot of technobable in the following articles, but the short versions are that there was a major security breach in relation to Samsung’s smart devices. And a particular model of D-Link webcam was so badly designed that it was possible to intercept the video stream without the owner’s knowledge. These kinds of thing are becoming increasingly prevalent. These two articles are from the last week alone.
Please think very carefully before you bring these devices into your home. Is convenience worth the associated risk?
With “GDPR go-live” just around the corner, one of the questions businesses need to be asking themselves is “Do we need to appoint a Data Protection Officer (DPO)?” Similarly, if your business asks you to act as its DPO, you should be asking what this involves, and whether you should accept the appointment.
Under GDPR, a business must accept considerable responsibilities towards its DPO. And the DPO takes on significant rights and obligations. The DPO shouldn’t simply be the person drawing the short straw in the organisation; it is a well known fact that the financial penalties under this legislation are potentially enormous. Correct appointment of a DPO is a crucial step towards mitigating data protection risks.
Do we need to appoint a DPO?
The relevant legislation is GDPR Article 37, which is entitled “Designation of the data protection officer”. The article states that an organisation must appoint a DPO if:
it is a public authority (other than a court of law); or
a primary function of the organisation involves “regular and systematic monitoring of data subjects on a large scale”; or
the organisation processes “special” personal data (see Article 9) or data about convictions/offences, on a large scale.
The first and third points are perhaps the easiest to understand. Less clear is the meaning of “regular and systematic monitoring”.
Section 5 of the guidelines provides clarification of this phrase, stating that it “clearly includes all forms of tracking and profiling on the internet, including for the purposes of behavioural advertising”. It then provides several useful examples that may fit the definition:
operating a telecommunications network
providing telecommunications services
email retargeting
data-driven marketing activities
profiling and scoring for purposes of risk assessment
location tracking
loyalty programs
behavioural advertising
monitoring of wellness, fitness and health data via wearable devices
closed circuit television
connected devices e.g. smart meters, smart cars, home automation, etc.
We don’t have a definition of “large scale”. The guidance offers some principles (how many data subjects, the geographical reach, etc.), but it is still a matter for the organisation to judge whether the data processing is large-scale. Suffice it to say: if you have a marketing database with hundreds of thousands of records, and you conduct targeted advertising campaigns, you’re probably caught by this requirement. Whatever you decide, make sure your decisions are recorded, in accordance with the principle of accountability.
One more point: even if GDPR doesn’t strictly oblige your organisation to appoint a DPO, it may be prudent to do so anyway. For one thing, it gives you a dedicated specialist, able to field queries related to data protection. For another, it is almost certainly good PR, since it communicates to partners, customers, etc., that you are taking data protection seriously. Bear in mind if you’re appointing a DPO, you must comply with the GDPR’s requirements relating to DPOs, whether or not the appointment is mandatory.
Characteristics of a DPO
Whether you’re appointing a DPO or you’ve been approached to act as your organisation’s DPO, it’s important to understand the obligations of the role. Articles 37 and 38 of the GDPR say that:
the DPO shall be selected on the basis of professional qualities
the DPO must have expert knowledge of data protection law and practices
the DPO may be a member of staff or a third party engaged for the purpose (e.g. a specialist data protection solicitor)
the DPO’s contact details must be published and made available to the ICO
the DPO is to be involved, promptly, in all data protection matters
the organisation must ensure the DPO is adequately resourced (e.g. with support staff and ongoing training)
the DPO must be able to operate independently, on the basis of the DPO’s own judgement, rather than under instruction from other members of the organisation
the DPO may not be dismissed or penalised for the proper execution of responsibilities
the DPO must report to the highest level of management within the organisation (e.g. directly to the board of directors)
the DPO must not be asked to perform any other duty that might give rise to a conflict of interests
So the DPO needs to understand this area of law – and understand it well. “Expert knowledge” is a reasonably high standard of capability. In almost all cases this will involve sending the DPO on appropriate training, especially if this is an internal appointment of someone without prior exposure to data protection law.
Should I accept an appointment as DPO?
On the basis of the above, if you are invited to act as your organisation’s Data Protection Officer, I would suggest asking the following questions:
Will I be reporting directly to the highest level of management in the organisation? (E.g. the board of directors or trustees.)
Could my other duties involve any conflict of interests? (E.g. a member of a marketing department may be asked to treat personal data with less care than that expected of a DPO.)
Do I have the requisite, detailed knowledge of data protection law and practice? Or if not, will I be appropriately trained before taking on the responsibility?
Will my organisation give me everything I need to do the job (including extra pairs of hands, where necessary)?
Will I be able to operate independently (rather than coming under pressure from senior members of staff)?
Is it likely that my organisation will take exception to my work as DPO and punish or dismiss me?
Can I be sure my other duties within the organisation won’t include determining how data is to be processed (thus breaking the independence principle)?
If your answer to any of these questions is “no”, you should decline the appointment – or at least discuss further until you are sure all the above conditions are satisfied. As a DPO you will be involved in many tasks related to data protection – managing subject access or right to be forgotten requests, conducting data protection impact assessments or legitimate impact assessments, keeping yourself apprised of the current state of the law, ensuring your organisation continues to comply with GDPR principles of privacy by design, minimisation, accountability and so on.
Make no mistake about it: it’s a big job, especially at a larger organisation. If you do decide to take on the role, I’d recommend taking a GDPR-specific data protection course with a reputable provider. IAPP offers the CIPP/E certification (Certified Information Privacy Professional/Europe), for example.
Tasks of the DPO
Article 39, GDPR states that the DPO should as a minimum do the following:
keep the organisation up to date with data protection obligations
monitor the organisation’s ongoing compliance
raise awareness of data protection requirements, throughout the organisation
advise and guide in relation to data protection impact assessments
cooperate and liaise with the Information Commissioner’s Office
always be mindful of privacy risks in relation to the organisation’s processing of data
So there’s a lot for the DPO to do. Given the scope of the organisation’s and the DPO’s responsibilities, many organisations may well choose to outsource this role. If you choose to pursue this path however, bear in mind that, depending on the size of your organisation, your third party may need to spend substantial time working with you – to the extent that appointing your own dedicated DPO may well be more cost-effective.
Quick orientation
In case you don’t know, Github is an online and largely open repository of code. Users can store code here for their open source projects, and track all changes to the code over time. Github code repositories usually offer public read access.
I know this is not new news. There have been multiplepublicisedincidents of Amazon AWS API keys being discovered in Github repositories. So we should have learnt our lesson. And yet, a security researcher told me this week that thousands of live credentials can be found within public Github repositories, if you know where to look. Using basic command line tools, commonly available on Linux/OpenBSD/Unix/MacOS, it is possible to discover live credentials for services like:
SMS messaging – with live credit cards attached
Password-based VNC connections to Internet-accessible computers. (I kid you not.)
AWS API keys. A favourite misuse of such keys is to set up bitcoin mining operations at someone else’s expense. My sources tells me of a hefty bill racked up at a UK business, after an employee accidentally uploaded their API keys to Github. That’s a bad day at the office.
KeePass files together with the master password. (You’re having a laugh.)
Full Netflix account details. (What the…?!)
Database connection credentials. That’s a huge problem if the database is so badly configured it’s public-facing.
Mitigation
Github has written a very useful article on removing sensitive information from repositories. Read it. (Or, you know, don’t put the sensitive information there in the first place.)
Have a look at this git pre-commit hook, which should help protect against this kind of mistake. (Note: read the comments on that gist.)
Run the script below against your own repositories (whether on Github or elsewhere) to find passwords in your code. Tweak it to search for other types of sensitive information.
If you find any passwords, keys or other credentials in your code, they may already be out in the wild. The safest thing to do is to change them.
Finding passwords in repositories
This shell script, kindly provided by my source, is one way to discover passwords hidden in your git commit history:
git log: view the history of code committed -p: show the differences only (in each new commit) -G'password.*{5,}': match lines that contain the word “password” with at least 5 characters afterwards awk: process through awk 'match($0,: look for matches in the entire line /password.*: This is the start of the regular expression; match “password”, with any number of characters afterwards ['\''"\[?&]: the extra apostrophes here are because we’re already using apostrophes in the shell command line; we’re matching against any single quote ('), double quote ("), open square bracket ([), question mark (?) or ampersand (&) (.*?): a lazy match of any character; this will generally return the passwords we’re looking for ['\''"\]=&]/,: again, the extra apostrophes here are for shell purposes; we’re matching against any single quote ('), double quote ("), closing square bracket (]), equals sign (=) or ampersand (&) arr): put the matches into “arr” { print arr[1]}': give us the first element from the matched line (anything matching afterwards is likely to be spurious) | grep: pass the result through grep -v '^\s*$': remove any lines that consist solely of white space | sort: sort the results (need to do this so that uniq can strip out duplicate matches) | uniq -c: remove duplicate results and prefix the output with the number of times the result occurred | sort -n: sort numerically (i.e. according to frequency of occurrence)
Example output follows; you’ll note that not everything returned is a password, but some definitely are:
Run this script over your own repositories; you may be surprised at the results. (You can substitute “key”, “secret” or “password” for password, for more hits.) If you find anything, and your repository is hosted openly on Github, you’ll need to take action promptly. Because anyone, repeat anyone can run this script against any open Github repo. If you’re not sure what to do, take another look at Github’s helpful article.
CCleaner is a popular program for cleaning up computers. Amongst the host of similar programs out there, CCleaner is the only one I’ve used and trusted, for many years. This week, that trust has been undermined fundamentally.
A version of CCleaner was released during August that contained malicious code, presumably without the developers’ knowledge – though it could well have been an inside job. Anyone installing CCleaner during August/early September may have installed the compromised version of CCleaner – version 5.33.
This is serious. CCleaner is powerful software. The injected code would run with at least the same power of CCleaner, which means it could potentially:
Watch your browsing activity
Capture passwords
Steal your files
Compromise your online banking credentials
Delete arbitrary data
Encrypt files
And so on.
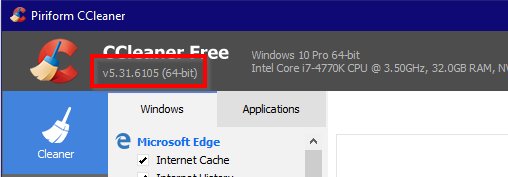
You can see if you’re at risk by running CCleaner and checking the version number:
If you have version 5.33 version installed, I strongly recommend taking the following steps:
Uninstall CCleaner immediately
Change all passwords you use with the affected computer – including online passwords, banking passwords, etc.
Review bank account and credit card statements for unusual activity
In many cases, you can add an extra layer of protection to your passwords by using “two factor authentication” (Google calls it 2-step verification). When logging into certain services, you will be prompted to enter a code from a text message or app. Even if your password has been compromised, two-factor authentication makes it that bit harder for others to gain access to your accounts.
For more information on two factor authentication (“2FA”):
Cisco’s security research team Talos advises that the ultimate target seems to be prominent tech companies. There’s evidence to suggest that a Chinese group has used this injected malware to launch further targeted attacks on companies like Sony, Intel, Samsung, Microsoft and several others. The most likely objective here is to steal intellectual property.
Should that make us any less concerned? Probably not. Such a serious compromise in a widespread, popular program undermines trust in software supply chains generally. There isn’t an awful lot we can do to defend against this sort of approach, other than to proceed with caution when installing any software. Best to stay away from the latest, bleeding-edge releases, perhaps.
Avast, the popular antivirus manufacturer owns CCleaner. If this can happen to a leading software security company, it can happen to anyone.
It’s the moment we’ve all been waiting for… The government has now published the Data Protection Bill, which is intended primarily to enshrine the equivalent EU law. This nascent legislation, which confirms the powers of the ICO, covers:
EU regulation 2016/679 (the General Data Protection Regulation), which comes into force in the EU on 25 May 2018
EU directive 2016/680 (the Law Enforcement Directive), which comes into force in the EU on 6 May 2018
The GDPR runs to 88 pages and the LED 43, so perhaps it’s no great surprise that the Data Protection Bill weighs in at a hefty 218 pages. (Wide margins, so that’s something.) It’s going to take a while to wade through, but what we can say immediately is that it’s every bit as bad as we feared. Certainly the €20m/4% fines have survived the translation into Britlaw.
Unlike GDPR, the DPB has a contents page, which is great. It’ll be that bit easier to look up how much trouble we’re in.
Expect the Bill to come into force largely unchanged, probably by next May and definitely before Brexit.
This website uses cookies to improve your experience. I will assume you're ok with this, but you can opt-out if you wish.AcceptRejectRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.