

Ever have this problem, launching a Docker container (in this case, Nginx on port 8000)?
Error: Unable to start container: Error response from daemon: Ports are not available: listen tcp 0.0.0.0:8000: bind: An attempt was made to access a socket in a way forbidden by its access permissions.
or maybe this problem, trying to run PHP’s built-in webserver?
php -S localhost:8080 [Fri Sep 11 09:00:09 2020] Failed to listen on localhost:8080 (reason: An attempt was made to access a socket in a way forbidden by its access permissions.)
Who to trust?
Like me, you may already have read many “solutions”, on a whole bunch of spammy websites. The “fixes” are often no more than workarounds – and in some cases, pretty bad workarounds, at that. Such as:
- Disable VPN
- Disable Internet Connection Sharing
- Disable third party firewall
- Disable antivirus (for goodness’ sake!)
More sensibly, use (e.g.) netstat to find out if something has already bound to the port.
None of these helped in my case. (Well I didn’t try disabling my antivirus or firewall, because c’mon!) Nothing was bound to the ports in question. I couldn’t disable ICS because I’m using its capabilities to provide NAT routing for Hyper-V networks.
The cause
It turns out the problem is down to Docker and Hyper-V reserving a shed load of ports. You can verify if this is the case for you by running the following command (which despite advice elsewhere on the internet does not need to be in an elevated PowerShell prompt; plain old no-privileges cmd will do):
netsh interface ipv4 show excludedportrange protocol=tcp
In my case, I could see that a lot of ports were reserved, between 1128 and 55437:
Start Port End Port ---------- -------- 1128 1227 1228 1327 1328 1427 1428 1527 1528 1627 1628 1727 1728 1827 1828 1927 1928 2027 [snip] 50000 50059 * 53610 53709 53710 53809 54210 54309 54610 54709 54710 54809 54910 55009 55113 55212 55214 55313 55338 55437 * - Administered port exclusions.
I confirmed that this is the issue by picking a port that hadn’t been reserved:
php -S localhost:50080 [Fri Sep 11 09:12:21 2020] PHP 7.4.8 Development Server (http://localhost:50080) started
(For me, the PHP web server would also start quite happily on port 80, incidentally. But you probably shouldn’t do that!)
People who have identified this issue tend to recommend disabling Hyper-V, excluding whatever ports you need and re-enabling Hyper-V. I’m nervous of that approach however, having spent a lot of time configuring Hyper-V networking and having seen this approach nuke networking in the past.
If you’re happy taking that approach, I suggest reading and understanding this Microsoft article. Personally, I prefer to approach this as follows.
Find gaps in port reservations
Hyper-V and Docker between them seem to reserve different sets of ports on each reboot. Helpful. You can look for gaps in the port reservations using the following method, but note that these gaps will not persist, without other measures. Here’s how to find the gaps:
- Run the
netshcommand above. - Copy and paste the output into Notepad++ and use search and replace (in regular expression mode) to turn all the spaces into tabs – replace
( +)with\t. - Copy and paste the result into Excel (which will now put all the ports nicely into cells.
- Use an Excel formula to identify gaps in the reserved ranges:
=IF(A4=(B3+1), "continuous", "## " & TEXT(A4-B3-1, "0") & " PORT GAP ##")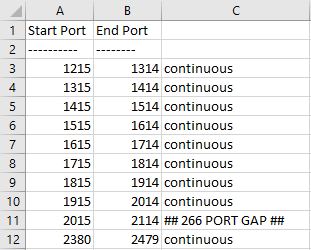
- Where “PORT GAP” appears, there is a gap between the end port on that line and the start port on the next (this would be 2115-2379 in the example above, which is 265 ports, inclusive).
As you can see, this approach does find you an available port (unless something else has bound to it):
php -S localhost:2115 [Fri Sep 11 09:36:58 2020] PHP 7.4.8 Development Server (http://localhost:2115) started
The fix: reserve your own ports
Well, two can play that game. Once you’ve found a gap, you can permanently reserve it for your own use. I found the largest gap between 12970 and 49670, so decided to reserve a memorable slice of ports: 20000- 21000. The appropriate incantation follows, which does need to be elevated this time. Swap port numbers and range to suit your environment and requirements:
netsh int ipv4 add excludedportrange protocol=tcp startport=20000 numberofports=1000 store=persistent
You will see that the range is now showing as administratively reserved (indicated by the asterisk):
netsh interface ipv4 show excludedportrange protocol=tcp Protocol tcp Port Exclusion Ranges Start Port End Port ---------- -------- 1215 1314 … 20000 20999 * … 51490 51589 - Administered port exclusions.
And once again, I can use a port within my preferred range:
php -S localhost:20080 [Fri Sep 11 10:37:23 2020] PHP 7.4.8 Development Server (http://localhost:20080) started
This exclusion persists between reboots and protects your range from being stolen by Hyper-V or anything else.
Angry budgie featured photo by Егор Камелев on Unsplash









 Unless you’ve been living in a cave for the last five years, you’ll have heard of cloud sync poster child
Unless you’ve been living in a cave for the last five years, you’ll have heard of cloud sync poster child 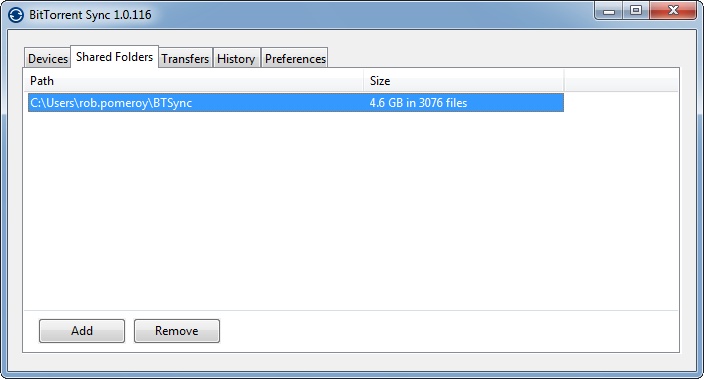
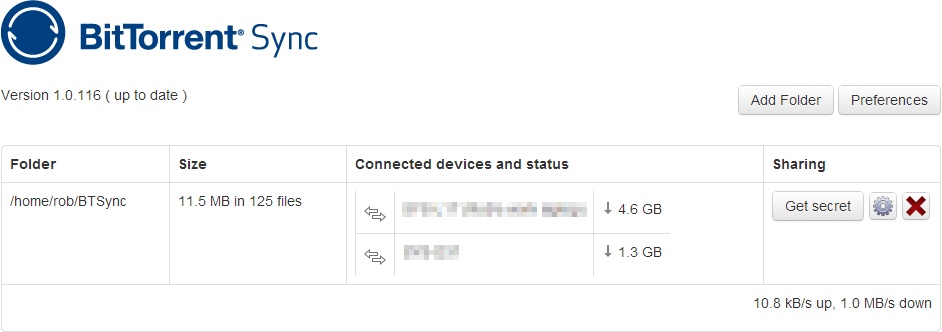

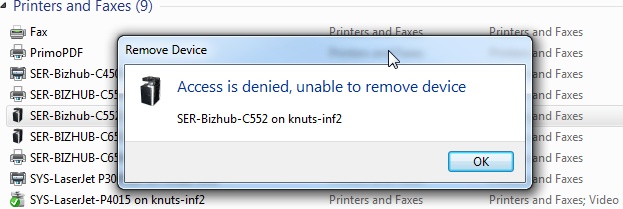
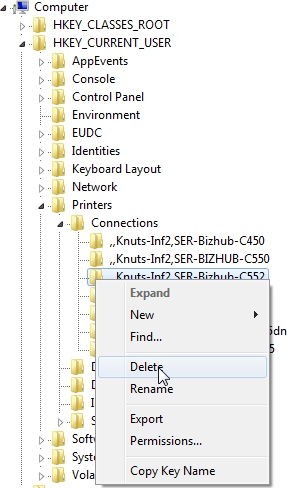
 I’m storing this as an aide memoire, really, but it may help you too.
I’m storing this as an aide memoire, really, but it may help you too.

 For almost all my previous web design, I’ve used
For almost all my previous web design, I’ve used 